OP2 API
Overview
The key characteristic of unstructured-mesh applications is the explicit connectivity required to specify the mesh and access data (indirectly) on neighboring mesh elements during computation over mesh elements. As such OP2 allows to describe an unstructured mesh by a number of sets, where depending on the application, these sets might be of nodes, edges, faces, cells of a variety of types, far-field boundary nodes, wall boundary faces, etc. Associated with these are data (e.g. coordinate data at nodes) and mappings to other sets (i.e. explicit connectivity, e.g. edge mapping to the two nodes at each end of the edge). All of the numerically-intensive operations can then be described as a loop over all members of a set, carrying out some operations on data associated directly with the set or with another set through a mapping.
Key Concepts and Structure
OP2 makes the important restriction that the order in which the function is applied to the members of the set must not affect the final result to within the limits of finite precision floating-point arithmetic. This allows the parallel implementation to choose its own ordering to achieve maximum parallel efficiency. Two other restrictions are that the sets and maps are static (i.e. they do not change) and the operands in the set operations are not referenced through a double level of mapping indirection (i.e. through a mapping to another set which in turn uses another mapping to data in a third set).
OP2 currently enables users to write a single program at a high-level API declaring the unstructured-mesh problem. Then the OP2 code-generator can be used to automatically generate a number of different paralleizations, using different parallel programing models, targeting modern multi-core and many-core hardware. The most mature parallel code generated by OP2 are :
Single-threaded on a CPU including code parallelized using SIMD
Multi-threaded using OpenMP for multicore CPU systems
Parallelized using CUDA for NVIDIA GPUs.
Further to these there are also in-development versions that can emit SYCL and AMD HIP for parallelization on a wider range of GPUs. All of the above can be combined with distributed-memory MPI parallelization to run of clusters of CPU or GPU nodes. The user can either use OP2’s parallel file I/O capabilities for HDF5 files with a specified structure, or perform their own parallel file I/O using custom MPI code.
Note
This page documents the C/C++ API. See OP2 Fortran 90 API for the equivalent Fortran API.
A computational project can be viewed as involving three steps:
Writing the program.
Debugging the program, often using a small testcase.
Running the program on increasingly large applications.
With OP2 we want to simplify the first two tasks, while providing as much performance as possible for the third.
To achieve the high performance for large applications, a code-generator is needed to generate the CUDA code for GPUs or OpenMP code for multicore x86 systems. However, to keep the initial development simple, a development single-threaded executable can be created without any special tools; the user’s main code is simply linked to a set of library routines, most of which do little more than error-checking to assist the debugging process by checking the correctness of the user’s program. Note that this single-threaded version will not execute efficiently. The code-generator is needed to generate efficient single-threaded (see 1. above) , SIMD and OpenMP code for CPU systems.
Fig. 1 shows the build process for a single thread CPU executable. The user’s main program (in this case jac.cpp) uses the OP2 header file op_seq.h and is linked to the appropriate OP2 libraries using g++, perhaps controlled by a Makefile.
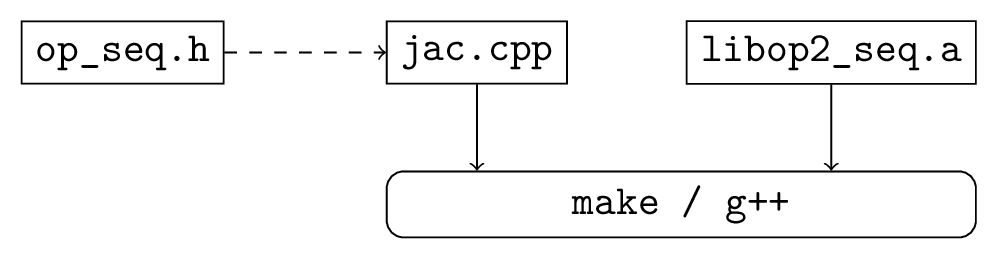
Fig. 1 Build process for a single-threaded development executable.
Fig. 2 shows the build process for the corresponding CUDA executable. The code-generator parses the user’s main program and produces a modified main program and a CUDA file which includes a separate file for each of the kernel functions. These are then compiled and linked to the OP libraries using g++ and the NVIDIA CUDA compiler nvcc, again perhaps controlled by a Makefile.
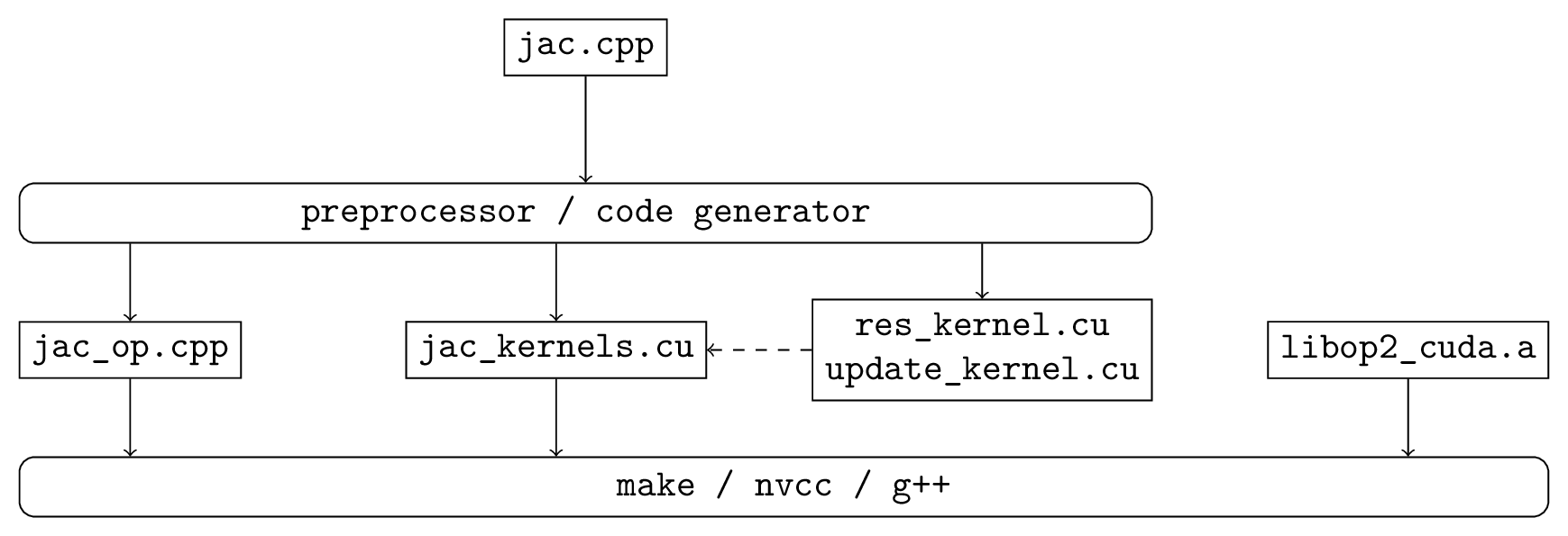
Fig. 2 Build process for a CUDA accelerated executable.
Fig. 3 shows the OpenMP build process which is very similar to the CUDA process except that it uses *.cpp files produced by the code-generator instead of *.cu files.
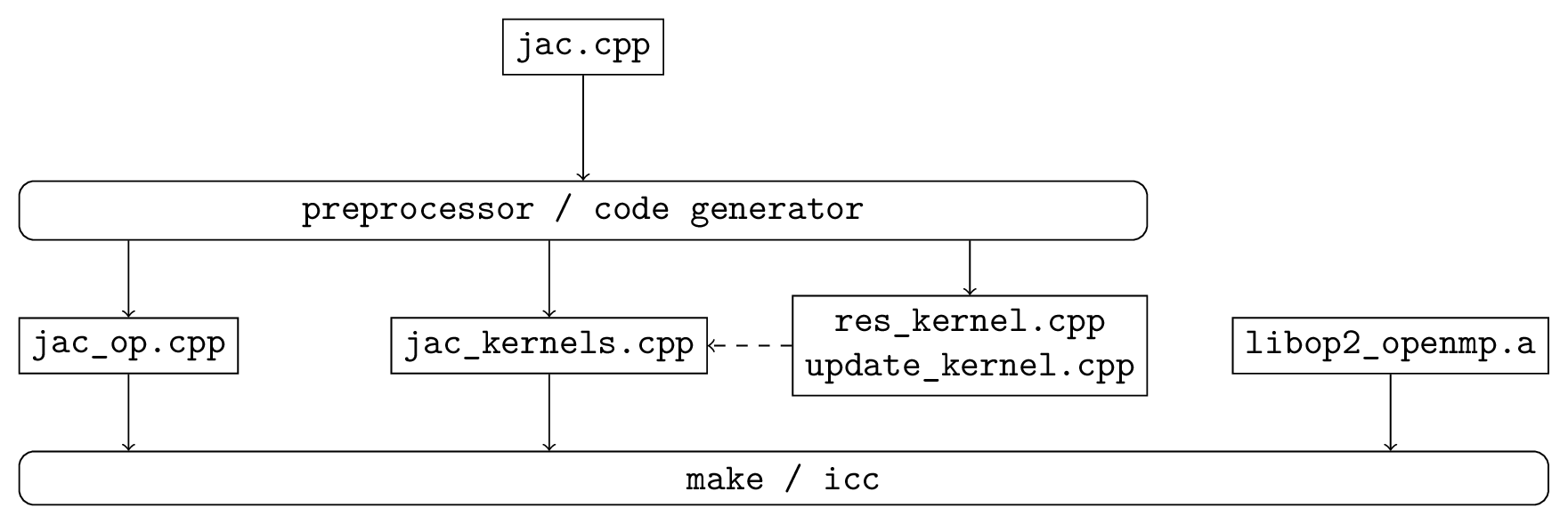
Fig. 3 Build process for an OpenMP accelerated executable.
In looking at the API specification, users may think it is somewhat verbose in places. For example, users have to re-supply information about the datatype of the datasets being used in a parallel loop. This is a deliberate choice to simplify the task of the code-generator, and therefore hopefully reduce the chance for errors. It is also motivated by the thought that “programming is easy; it’s debugging which is difficult”: writing code isn’t time-consuming, it’s correcting it which takes the time. Therefore, it’s not unreasonable to ask the programmer to supply redundant information, but be assured that the code-generator or library will check that all redundant information is self-consistent. If you declare a dataset as being of type OP_DOUBLE and later say that it is of type OP_FLOAT this will be flagged up as an error at run-time.
OP2 C/C++ API
Index Types
OP2 introduces two typedef aliases for index types to support large-scale meshes with more than 2 billion elements:
-
type idx_l_t
Alias for
int. Used for local (per-process) set sizes and mapping table entries.
-
type idx_g_t
Alias for
long long. Used for global element counts and offsets across all MPI processes.
Initialisation and Termination
-
void op_init(int argc, char **argv, int diags_level)
This routine must be called before all other OP routines. Under MPI back-ends, this routine also calls
MPI_Init()unless its already called previously.- Parameters:
argc – The number of command line arguments.
argv – The command line arguments, as passed to
main().diags_level – Determines the level of debugging diagnostics and reporting to be performed.
The values for diags_level are as follows:
0: None.
1: Error-checking.
2: Info on plan construction.
3: Report execution of parallel loops.
4: Report use of old plans.
7: Report positive checks in
op_plan_check()
-
void op_exit()
This routine must be called last to cleanly terminate the OP2 runtime. Under MPI back-ends, this routine also calls
MPI_Finalize()unless its has been called previously. A runtime error will occur ifMPI_Finalize()is called afterop_exit().
-
op_set op_decl_set(idx_l_t size, char *name)
This routine declares a set.
- Parameters:
size – Number of set elements.
name – A name to be used for output diagnostics.
- Returns:
A set ID.
-
op_map op_decl_map(op_set from, op_set to, int dim, idx_l_t *imap, char *name)
This routine defines a mapping between sets.
- Parameters:
from – Source set.
to – Destination set.
dim – Number of mappings per source element.
imap – Mapping table, using local (per-process) indices of type
idx_l_t.name – A name to be used for output diagnostics.
-
op_map op_decl_map_long(op_set from, op_set to, int dim, idx_g_t *imap, char *name)
Equivalent to
op_decl_map()but accepts a mapping table with global indices of typeidx_g_t. Use this variant when the mesh contains more thanINT_MAXelements globally.- Parameters:
from – Source set.
to – Destination set.
dim – Number of mappings per source element.
imap – Mapping table, using global indices of type
idx_g_t.name – A name to be used for output diagnostics.
-
void op_partition(char *lib_name, char *lib_routine, op_set prime_set, op_map prime_map, op_dat coords)
This routine controls the partitioning of the sets used for distributed memory parallel execution.
- Parameters:
lib_name – The partitioning library to use, see below.
lib_routine – The partitioning algorithm to use.
prime_set – Specifies the primary set to be partitioned.
prime_map – Specifies the map to be used to create adjacency lists for the prime_set. Required if using "KWAY" or "GEOMKWAY".
coords – Specifies the geometric coordinates of the prime_set. Required if using "GEOM" or "GEOMKWAY".
The current options for lib_name are:
"PTSCOTCH": The PT-Scotch library.
"PARMETIS": The ParMETIS library.
"KAHIP": The KaHIP library.
"INERTIAL": Internal 3D recursive inertial bisection partitioning.
"EXTERNAL": External partitioning optionally read in when using HDF5 I/O.
"RANDOM": Random partitioning, intended for debugging purposes.
The options for lib_routine when using "PTSCOTCH" or "KAHIP" are:
"KWAY": K-way graph partitioning.
The options for lib_routine when using "PARMETIS" are:
"KWAY": K-way graph partitioning.
"GEOM": Geometric graph partitioning.
"GEOMKWAY": Geometric followed by k-way graph partitioning.
-
void op_decl_const(int dim, char *type, T *dat)
This routine defines constant data with global scope that can be used in kernel functions.
- Parameters:
dim – Number of data elements. For maximum efficiency this should be an integer literal.
type – The type of the data as a string. This can be either intrinsic ("float", "double", "int", "uint", "ll", "ull", or "bool") or user-defined.
dat – A pointer to the data, checked for type consistency at run-time.
Note
If dim is 1 then the variable is available in the kernel functions with type T, otherwise it will be available with type T*.
Warning
If the executable is not preprocessed, as is the case with the development sequential build, then you must define an equivalent global scope variable to use the data within the kernels.
-
op_dat op_decl_dat(op_set set, int dim, char *type, T *data, char *name)
This routine defines a dataset.
- Parameters:
set – The set the data is associated with.
dim – Number of data elements per set element.
type – The datatype as a string, as with
op_decl_const(). A qualifier may be added to control data layout - see Dataset Layout.data – Input data of type
T(checked for consistency with type at run-time). The data must be provided in AoS form with each of the dim elements per set element contiguous in memory.name – A name to be used for output diagnostics.
Note
At present dim must be an integer literal. This restriction will be removed in the future but an integer literal will remain more efficient.
-
op_dat op_decl_dat_temp(op_set set, int dim, char *type, T *data, char *name)
Equivalent to
op_decl_dat()but the dataset may be released early withop_free_dat_temp().
-
void op_free_dat_temp(op_dat dat)
This routine releases a temporary dataset defined with
op_decl_dat_temp()- Parameters:
dat – The dataset to free.
Dataset Layout
The dataset storage in OP2 can be configured to use either AoS (Array of Structs) or SoA (Struct of Arrays) layouts. As a default the AoS layout is used, matching what is supplied to op_decl_dat(), however depending on the access patterns of the kernels and the target hardware platform the SoA layout may perform favourably.
OP2 can be directed to ues SoA layout storage by setting the environment variable OP_AUTO_SOA=1 prior to code translation, or by appending :soa to the type strings in the op_decl_dat() calls. The data supplied by the user should remain in the AoS layout.
Parallel Loops
-
void op_par_loop(void (*kernel)(...), char *name, op_set set, ...)
This routine executes a parallelised loop over the given set, with arguments provided by the
op_arg_gbl(),op_arg_dat(), andop_opt_arg_dat()routines.- Parameters:
kernel – The kernel function to execute. The number of arguments to the kernel should match the number of
op_argarguments provided to this routine.name – A name to be used for output diagnostics.
set – The set to loop over.
... – The
op_argarguments passed to each invocation of the kernel.
-
op_arg op_arg_gbl(T *data, int dim, char *type, op_access acc)
This routine defines an
op_argthat may be used either to pass non-constant read-only data or to compute a global sum, maximum or minimum.- Parameters:
data – Source or destination data array.
dim – Number of data elements.
type – The datatype as a string. This is checked for consistency with data at run-time.
acc – The access type.
Valid access types for this routine are:
OP_READ: Read-only.OP_INC: Global reduction to compute a sum.OP_MAX: Global reduction to compute a maximum.OP_MIN: Global reduction to compute a minimum.OP_WORK: Per-thread scratch space initialized with user-defined array values.
Note
OP_WORKis similar toOP_READ, but is intended for cases where per-thread work arrays are too large to sensibly fit in GPU register space.
-
op_arg op_arg_dat(op_dat dat, int idx, op_map map, int dim, char *type, op_access acc)
This routine defines an
op_argthat can be used to pass a dataset either directly attached to the targetop_setor attached to anop_setreachable through a mapping.- Parameters:
dat – The dataset.
idx – The per-set-element index into the map to use. You may pass a negative value here to use a range of indicies - see below. This argument is ignored if the identity mapping is used.
map – The mapping to use. Pass
OP_IDfor the identity mapping if no mapping indirection is required.dim – The dimension of the dataset, checked for consistency at run-time.
type – The datatype of the dataset as a string, checked for consistency at run-time.
acc – The access type.
Valid access types for this routine are:
OP_READ: Read-only.OP_WRITE: Write-only.OP_RW: Read and write.OP_INC: Increment or global reduction to compute a sum.
The idx parameter accepts both positive values to specify a single per-element map index, where the kernel is passed a single dimension array of data, or negative values to specify a range of mapping indicies leading to the kernel being passed a two-dimensional array of data. If a negative index is provided the first -idx mapping indicies are provided to the kernel.
Consider the example of a kernel that is executed over a set of triangles, and is supplied the verticies via arguments. Using positive idx you would need one
op_argper vertex, leading to a kernel declaration similar to:void kernel(float *v1, float *v2, float *v3, ...);
Alternatively, using a negative idx of -3 allows a more succinct declaration:
void kernel(float **v[3], ...);
Warning
OP_WRITEandOP_RWaccesses must not have any potential data conflicts. This means that two different elements of the set cannot, through a map, reference the same elements of the dataset.Furthermore with
OP_WRITEthe kernel function must set the value of all dim components of the dataset. If this is not possible thenOP_RWaccess should be specified.Note
At present dim must be an integer literal. This restriction will be removed in the future but an integer literal will remain more efficient.
-
op_arg op_opt_arg_dat(op_dat dat, int idx, op_map map, int dim, char *type, op_access acc, int flag)
This routine is equivalent to
op_arg_dat()except for an extra flag parameter that governs whether the argument will be used (non-zero) or not (zero). This is intended to ease development of large application codes where many features may be enabled or disabled based on flags.The argument must not be dereferenced in the user kernel if flag is set to zero. If the value of the flag needs to be passed to the kernel then use an additional
op_arg_gbl()argument.
-
op_arg op_arg_idx(int idx, op_map map)
This routine is used to provide the (global) index mapping information to be used within a kernel function.
- Parameters:
idx – The per-set-element index into the map to use. You may pass a -1 if the identity mapping is used.
map – The mapping to use. Pass
OP_IDfor the identity mapping if no mapping indirection is required.
-
op_arg op_arg_info(T *data, int dim, char *type, int ref)
This routine is used with argmin/argmax operations to determine the (global) index at which the minimum or maximum value occurs. It is intended to be used in conjunction with
op_arg_idx(). The value provided through this argument (for example, the coordinates of the current node) is returned from the location where the corresponding minimum or maximum is found.This is a C++ template function; the element size is deduced automatically from the type
T.- Parameters:
data – The data to be associated with the index returned by the argmin/argmax operation.
dim – The number of data elements.
type – The datatype, specified as a string, as with
op_decl_const().ref – Reference index.
Warning
This routine is only valid when used in conjunction with
op_arg_gbl()withOP_MINorOP_MAXaccess types.
HDF5 I/O
HDF5 has become the de facto format for parallel file I/O, with various other standards like CGNS layered on top. To make it as easy as possible for users to develop distributed-memory OP2 applications, we provide alternatives to some of the OP2 routines in which the data is read by OP2 from an HDF5 file, instead of being supplied by the user. This is particularly useful for distributed memory MPI systems where the user would otherwise have to manually scatter data arrays over nodes prior to initialisation.
-
op_set op_decl_set_hdf5(char *file, char *name)
Equivalent to
op_decl_set()but takes a file instead of size, reading in the set size from the HDF5 file using the keyword name.
-
op_map op_decl_map_hdf5(op_set from, op_set to, int dim, char *file, char *name)
Equivalent to
op_decl_map()but takes a file instead of imap, reading in the mappiing table from the HDF5 file using the keyword name.
-
op_dat op_decl_dat_hdf5(op_set set, int dim, char *type, char *file, char *name)
Equivalent to
op_decl_dat()but takes a file instead of data, reading in the dataset from the HDF5 file using the keyword name.
-
void op_get_const_hdf5(char *name, int dim, char *type, char *data, char *file)
This routine reads constant data from an HDF5 file.
- Parameters:
name – The name of the dataset in the HDF5 file.
dim – The number of data elements in the dataset.
type – The string type of the data.
data – A user-supplied array of at least dim capacity to read the data into.
file – The HDF5 file to read the data from.
Note
To use the read data from within a kernel function you must declare it with
op_decl_const()Warning
The number of data elements specified by the dim parameter must match the number of data elements present in the HDF5 file.
MPI without HDF5 I/O
If you wish to use the MPI executables but don’t want to use the OP2 HDF5 support, you may perform your own file I/O and then provide the data to OP2 using the normal routines. The behaviour of these routines under MPI is as follows:
op_decl_set(): The size parameter is the number of elements provided by this MPI process.op_decl_map(): The imap parameter provides the part of the mapping table corresponding to the processes share of the from set, using localidx_l_tindices. Useop_decl_map_long()if globalidx_g_tindices are available instead.op_decl_dat(): The data parameter provides the part of the dataset corresponding to the processes share of the set set.
For example if an application has 4 processes, 4M nodes and 16M edges, then each process might be responsible for providing 1M nodes and 4M edges.
Note
This is effectively using simple contiguous block partitioning of the datasets, but it is important to note that this is strictly for I/O and this partitioning will not be used for the parallel computation. OP2 will re-partition the datasets, re-number the mapping tables and then shuffle the data between the MPI processes as required.
Other I/O and Utilities
-
void op_printf(const char *format, ...)
This routine wraps the standard
printf()but only prints on theMPI_ROOTprocess.
-
void op_fetch_data(op_dat dat, T *data)
This routine copies data held in an
op_datfrom the OP2 backend into a user allocated memory buffer.- Parameters:
dat – The dataset to copy from.
data – The user allocated buffer to copy into.
Warning
The memory buffer provided by the user must be large enough to hold all elements in the
op_dat.
-
void op_fetch_data_idx(op_dat dat, T *data, int low, int high)
This routine is equivalent to
op_fetch_data()but with extra parameters to specify the range of data elements to fetch from theop_dat.- Parameters:
dat – The dataset to copy from.
data – The user allocated buffer to copy into.
low – The index of the first element to be fetched.
high – The index of the last element to be fetched.
-
void op_fetch_data_hdf5_file(op_dat dat, const char *file_name)
This routine writes the data held in an
op_datfrom the OP2 backend into an HDF5 file.- Parameters:
dat – The source dataset.
file – The name of the HDF5 file to write the dataset into.
-
void op_print_dat_to_binfile(op_dat dat, const char *file_name)
This routine writes the data held in an
op_datfrom the OP2 backend into a binary file.- Parameters:
dat – The source dataset.
file – The name of the binary file to write the dataset into.
-
void op_print_dat_to_txtfile(op_dat dat, const char *file_name)
This routine writes the data held in an
op_datfrom the OP2 backend into a text file.- Parameters:
dat – The source dataset.
file – The name of the text file to write the dataset into.
-
int op_is_root()
This routine allows a convenient way to test if the current process is the MPI root process.
- Return values:
1 – Process is the MPI root.
0 – Process is not the MPI root.
-
idx_g_t op_get_size(op_set set)
This routine gets the global size of an
op_set.- Parameters:
set – The set to query.
- Returns:
The number of elements in the set across all processes.
-
idx_g_t op_get_global_set_offset(op_set set)
In an MPI execution, returns the global index offset for the partition of set owned by the current rank. That is, the first element owned by this rank has global index
op_get_global_set_offset(set). Returns 0 in non-MPI builds.- Parameters:
set – The set to query.
- Returns:
The global element offset for the current MPI rank.
-
void op_dump_to_hdf5(const char *file_name)
This routine dumps the contents of all
op_sets,op_dats andop_maps to an HDF5 file as held internally by OP2, intended for debugging purposes.- Parameters:
file_name – The name of the HDF5 file to write the data into.
-
void op_timers(double *cpu, double *et)
This routine provides the current wall-clock time in seconds since the Epoch using
gettimeofday().- Parameters:
cpu – Unused.
et – A variable to hold the time.
-
void op_timing_output()
This routine prints OP2 performance details.
-
void op_timings_to_csv(const char *file_name)
This routine writes OP2 performance details to the specified CSV file. For MPI executables the timings are broken down by rank. For OpenMP executables with the
OP_TIME_THREADSenvironment variable set, the timings are broken down by thread. For MPI + OpenMP executables withOP_TIME_THREADSset the timings are broken down per thread per rank.- Parameters:
file_name – The name of the CSV file to write.
Profiling API
The op_profile API (op2/include/op_profile.h) provides a tree-based timing and instrumentation facility for OP2 applications. It replaces the older op_timers / op_timing_output pattern with a structured, hierarchical timing tree that can be printed to stdout or exported to JSON.
The translator-generated kernel code automatically inserts op_profile_enter_kernel calls; application code uses the simpler op_profile_start / op_profile_enter / op_profile_end functions to time outer sections.
Typical usage:
op_profile_start("MyApp"); // initialise, name the root
op_profile_enter("Setup"); // begin a named section
/* ... setup work ... */
op_profile_next("Computation"); // exit "Setup", enter "Computation"
/* ... main loop ... */
op_profile_end(); // close all open sections
op_profile_output(); // print summary; write JSON if OP_PROFILE_JSON_OUTPUT is set
-
void op_profile_start(const char *name)
Initialise the profiling system and set the root application name. Must be called before any other
op_profile_*function. ReadsOP_PROFILE_LEVELfrom the environment at this point.- Parameters:
name – A descriptive name for the application (used as the root label in the timing tree).
-
void op_profile_enter(const char *name)
Begin a named timing section, pushing it onto the timing stack. Device synchronisation is performed before the timer starts (for accurate GPU timings).
- Parameters:
name – A descriptive name for the section.
-
void op_profile_enter_kernel(const char *name, const char *target, const char *variant)
Enter a kernel-level timing section. Called automatically by translator-generated kernel code; do not call manually in application code.
- Parameters:
name – Kernel name.
target – Backend target string (e.g.
"cuda","openmp").variant – Kernel variant string.
-
void op_profile_next(const char *name)
Convenience helper equivalent to calling
op_profile_exit()followed immediately byop_profile_enter()with the new name.- Parameters:
name – The name of the next section to enter.
-
void op_profile_exit()
Close the innermost open timing section, recording elapsed time.
-
void op_profile_end()
End profiling, closing all remaining open sections.
-
void op_profile_output()
Pretty-print the timing tree to stdout. If the
OP_PROFILE_JSON_OUTPUTenvironment variable is set, also writes the tree to that file in JSON format. For MPI builds, timing trees are collected from all ranks and combined before printing.
-
void op_profile_output_json(const char *filename)
Write the timing tree to filename in JSON format. For MPI builds, trees from all ranks are combined first.
- Parameters:
filename – Path to the output JSON file.
-
void op_diagnostic_output()
This routine prints diagnostics relating to sets, mappings and datasets.
Runtime Environment Variables
The following environment variables can be set at run time to control OP2 behaviour:
Variable |
Description |
|---|---|
|
Set to |
|
Set to |
|
Integer. Caps the maximum number of OpenMP threads used inside JIT-compiled ( |
|
Set to |
|
Controls the detail level of the |
|
If set to a file path, |
OP2 Fortran 90 API
The Fortran 90 API mirrors the C/C++ API closely. The same concepts — sets, maps, dats, constants, and parallel loops — apply directly. This section documents the key differences in calling convention and type syntax.
Note
A complete worked example using the Fortran API can be found in apps/fortran/airfoil/airfoil.F90.
Initialisation and Shutdown
call op_init_base(diags_level, 0)
call op_exit()
op_init_basetakesdiags_levelas the first argument (same levels asop_init()). Under MPI builds it also callsMPI_Init.op_exitfinalises OP2 and under MPI builds callsMPI_Finalize.
Index Types
The Fortran equivalents of the C index types are:
Declaring Mesh Data
! Sets (size is integer(4) — local element count)
call op_decl_set(size, set_handle, "name")
! Maps with local indices (integer(4) array)
call op_decl_map(from_set, to_set, dim, imap_array, map_handle, "name")
! Maps with global indices (integer(8) array — for meshes > INT_MAX elements)
call op_decl_map_long(from_set, to_set, dim, imap_array_long, map_handle, "name")
! Datasets
call op_decl_dat(set, dim, "type", data_array, dat_handle, "name")
! Global constants
call op_decl_const(data_variable, dim, "type")
Key differences from C/C++:
Each declaration takes an output handle (
set_handle,map_handle,dat_handle) as an extra argument to receive the OP2 object.op_decl_consttakes the data variable first, followed bydimand"type"— the reverse of the C++ argument order.Fortran type strings use Fortran syntax:
"real(8)"(double precision),"real(4)"(single precision),"integer(4)"(32-bit integer).Use
op_decl_map_longwhen the mapping table uses globalinteger(8)indices (i.e. the mesh has more than2^{31}-1elements globally).
HDF5 Variants
call op_decl_set_hdf5(size_out, set_handle, file_name, "name")
call op_decl_map_hdf5(from_set, to_set, dim, map_handle, file_name, "name", stat)
call op_decl_dat_hdf5(set, dim, dat_handle, "type", file_name, "name", stat)
Parallel Loops
In the Fortran API the parallel loop call is named with the number of arguments:
call op_par_loop_N(kernel_subroutine, iteration_set, &
op_arg_dat(dat, idx, map, dim, "type", access), &
...)
Nis the total number ofop_arg_dat/op_arg_gblarguments passed.The kernel is passed as a subroutine reference.
op_arg_datandop_arg_gblhave the same signature as in C/C++, using the sameOP_READ,OP_WRITE,OP_RW,OP_INC,OP_IDconstants.
Example from the Fortran Airfoil benchmark:
! Direct loop (2 arguments)
call op_par_loop_2(save_soln, cells, &
op_arg_dat(p_q, -1, OP_ID, 4, "real(8)", OP_READ), &
op_arg_dat(p_qold, -1, OP_ID, 4, "real(8)", OP_WRITE))
! Indirect loop (8 arguments)
call op_par_loop_8(res_calc, edges, &
op_arg_dat(p_x, 1, pedge, 2, "real(8)", OP_READ), &
op_arg_dat(p_x, 2, pedge, 2, "real(8)", OP_READ), &
op_arg_dat(p_q, 1, pecell, 4, "real(8)", OP_READ), &
op_arg_dat(p_q, 2, pecell, 4, "real(8)", OP_READ), &
op_arg_dat(p_adt, 1, pecell, 1, "real(8)", OP_READ), &
op_arg_dat(p_adt, 2, pecell, 1, "real(8)", OP_READ), &
op_arg_dat(p_res, 1, pecell, 4, "real(8)", OP_INC), &
op_arg_dat(p_res, 2, pecell, 4, "real(8)", OP_INC))
! Loop with global reduction (8 arguments, including op_arg_gbl)
call op_par_loop_8(update, cells, &
op_arg_dat(p_qold, -1, OP_ID, 4, "real(8)", OP_READ), &
op_arg_dat(p_q, -1, OP_ID, 4, "real(8)", OP_WRITE), &
op_arg_dat(p_res, -1, OP_ID, 4, "real(8)", OP_RW), &
op_arg_dat(p_adt, -1, OP_ID, 1, "real(8)", OP_READ), &
op_arg_gbl(rms, 1, "real(8)", OP_INC))
Note
op_par_loop_N is defined for each value of N used in the application. The OP2 Fortran library provides pre-built stubs for common arities, but the code translator generates the correct loop host for each kernel.
Mesh Partitioning
call op_partition("PARMETIS", "KWAY", prime_set, prime_map, coords_dat)
The arguments and valid lib_name / lib_routine options are identical to the C/C++ op_partition().
Utility Functions
integer(8) :: gsize, offset
gsize = op_get_size(set_handle) ! global element count across all ranks
offset = op_get_global_set_offset(set_handle) ! global index of first element on this rank
op_get_sizereturnsinteger(8)— the total number of elements in the set across all MPI processes. Equivalent toop_get_size().op_get_global_set_offsetreturnsinteger(8)— the global index of the first element owned by the current MPI rank. Returns 0 in non-MPI builds. Equivalent toop_get_global_set_offset().
Build Configuration
Fortran application variants are prefixed with f_ in the Make build system:
Target |
Description |
|---|---|
|
Sequential Fortran build. |
|
OpenMP multi-threaded Fortran build. |
|
Native CUDA Fortran build (requires NVHPC). |
|
Fortran + C CUDA JIT build (recommended GPU target). |
|
Fortran + C HIP JIT build. |
|
Distributed-memory MPI variant of any of the above. |
For the translator invocation for Fortran sources, see Code Generation.
Timers and Profiling
real(8) :: et
call op_timers(et) ! wall-clock time in seconds (since the Epoch)
call op_timing_output() ! print OP2 per-kernel timing summary to stdout
op_timers(et)fillsetwith the current wall-clock time in seconds. Call it before and after a region to measure elapsed time.op_timing_output()prints a per-kernel table identical to the C/C++op_timing_output().
Note
Unlike the C/C++ op_timers(), the Fortran version takes only one argument (the wall-clock time et); the cpu argument is omitted.
The op_profile profiling API is also available in Fortran with identical semantics to the C/C++ interface:
call op_profile_start("MyApp")
call op_profile_enter("Setup")
! ... setup work ...
call op_profile_next("Computation")
! ... main loop ...
call op_profile_end()
call op_profile_output()
The available Fortran subroutines mirror the C API: op_profile_start, op_profile_enter, op_profile_enter_kernel, op_profile_next, op_profile_exit, op_profile_end, op_profile_output, and op_profile_output_json. The OP_PROFILE_LEVEL and OP_PROFILE_JSON_OUTPUT environment variables apply in Fortran builds identically to C/C++ builds.